
My first experience with relation database was in 1996. It was Oracle 7, and it was also my first experience with SQL. I was impressed by the potential of relational database management systems (RDBMS) and SQL as well. That time the choice for relation databases was not huge. Not many open-source versions were available at that time, but they started to evolve (e.g. Postgres, MySQL). Mostly RDBMS dominated the market. This fact has led to the situation that relational databases were used for storing different kind of data, not only relational nature data used to store in the relation database. Interesting situations developed within enterprises. Vendor management teams arranged licence agreements for the usage of RDBMS with one or (seldom) two well-known RDBMS providers. These agreements were prolonged for years, and even now some enterprises have this limited product portfolio. As a result, there was often only a single technology option for data storage. In many scenarios a RDBMS is not an optimal choice, not only from the technical point of view, but also from the commercial point of view.
The situation with the available database options was changed in late 90/early 2000 as new open-source databases appeared. Later, with evolving of cloud providers, the grow of databases options was accelerated. Most cloud providers have different kind of databases in their service portfolio: RDBMS, NoSQL, document-based, graph-based, etc.
Therefore, for architects and other roles who are involved in the database decision process the choice of a suitable database became not an easy task. Great data storage availability makes the decision difficult. Many factors should be considered and analysed while choosing the most suitable data storage option. The supported application architectures and styles have also changed – for example a microservice architecture uses different data storage capabilities for storing different types of data.
An important concept to bear in mind is that data modelling in nonrelational databases requires a new set of skills for RDBMS users who are accustomed to building third normal form (3NF)[i] data models in entity relationship[ii] diagrams (ERDs). Nonrelational data stores differ in their characteristics. In addition, many vendors now offer multi-model data stores that combine many of the categories of both relational and nonrelational data stores. For instance, relational databases have added support for JSON documents. However, their support for JSON documents is not the same as native support to handle semi-structured and unstructured data.
The process of choosing a Database option should be now based on a structured evaluation of different criteria and calculating return of investment. In each scenario the choice should be carefully done considering different criteria, covering the whole range from the technology perspective to the financial aspect. Each aspect could have different weight in different organisations.
Consideration.
- As the first aspect to consider I would suggest the data type: structured, unstructured, or semi-structured and how the data should be stored, queried, and updated. Some kind of data could seem to be unstructured, but it should be queried as structured data. This will have influence on the way these data stored and processed (or pre-processed).
- Decide whether transactional and ACID[iii] guarantees are a mandatory requirement. Different database providers tend to state that their database is ACID complaint, but it can be true only to some extent.
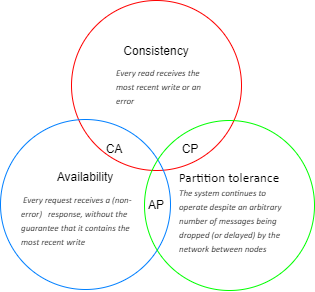
- Consistency, availability, partition tolerance. According to the CAP theorem[iv]:
it is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees:
- Consistency: Every read receives the most recent write or an error
- Availability: Every request receives a (non-error) response, without the guarantee that it contains the most recent write
- Partition tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes
NoSQL databases are classified based on the two CAP characteristics they support:
CP: Consistency and Partition.
AP: Availability and Partition.
CA: Consistency and Availability.
Understanding the CAP theorem can help you choose the best database when designing a microservices-based application running from multiple locations.
- Decide any other functional and non-functional database requirements and priorities:
- security
- scalability
- robustness and reliability
- performance
- In-database analytics and monitoring
- availability of related skills
- others…
- Determine if an open-source database is an option, or if a vendor-based solution with SLA is required.
- Identify any cost constraints and/or budgets.
The consideration of these topics should help you to decide which database system (e.g., relational, NoSQL, NewSQL) will satisfy your needs the best.
Relation Databases are recommended to use in cases you need:
- Mission-critical applications: These will satisfy strong compliance, high throughput, and high performance for a wide range of queries and updates are paramount. Relational databases are still the predominant systems of a record for operational transactions.
- SQL-based access.
- Predictability: Relational databases offer well-understood performance, consistency, reliability, scalability and availability, meeting requirements for concurrent access with predictable cost.
- Reliability: Mature, well-tested products ensure reliability and offer easy availability of necessary skill sets.
- Manageability: RDBMS have wide range of tools and possibilities for easy manage the database.
Key-Value Databases are recommended to use in cases you need:
- Low latency writes or high insert performance.
- Storing high-frequency inserts, such as web session logs, etc.
But do not use it for applications that require complex queries or SQL access.
Document Database are recommended to use in cases you need:
- Dynamic data that need a document model, such as web interaction or message-centric B2B applications.
- Content management, personalization, social/mobile and similar use cases.
But do not use it for data warehouses or data marts. Not all document databases provide strong consistency or support for complex SQL queries requiring joins or filters.
Graph Database are recommended to use in cases you need:
- OLTP on relationship-rich data, such as in social or recommendation use cases, to gain very high performance and ACID support for CRUD operations
- To build knowledge graphs to share and publish open data, data catalogs, metadata management, and for semantic or text processing.
- To model complex domains, such as route optimization and recommendation engines.
But do not use graph databases for aggregations, BI and queries involving joins.
Time Series Database are recommended to use in cases you need:
- IoT and especially IIoT use cases that are mission-critical and that require integration between IT and operational technology (OT).
- To store application metrics and operations monitoring, etc.
Summary
Databases were and are always mission-critical. Now, the stakes are growing ever higher as a wider group of users demand more current data and advanced analytics. Selecting the wrong type of data store can have devastating ramifications, including inability to meet performance, availability, or cost requirements.
New technologies emerging so fast that making specific recommendations would not be the right approach here. But it is possible to find the right solution considering the topics described above.
[i] https://en.wikipedia.org/wiki/Third_normal_form
[ii] https://en.wikipedia.org/wiki/Entity%E2%80%93relationship_model
[iii] https://en.wikipedia.org/wiki/ACID
[iv] https://en.wikipedia.org/wiki/CAP_theorem